
Approach shows ANN, CNN and LSTM model respectively for speech emotion analysis using three distinct
emotional labels: anger, sadness, and happiness. The approach involves the extraction of audio features,
specifically Mel-frequency cepstral coefficients (MFCC), Pitch Chroma Patterns (PCP), and
Linear Prediction Coefficients (LPC), to capture relevant information from the raw audio signals.
The proposed methodology employs a threefold strategy, wherein separate models are trained for each emotion category.
This tailored approach aims to enhance the model's sensitivity to the subtle nuances and distinctive patterns associated with anger,
sadness, and happiness. The audio datasets used for training and evaluation consist of a diverse set of samples encompassing various
speakers, contexts, and emotional intensities.
The feature extraction process involves transforming the raw audio signals into representative feature vectors,
which are then used as input to the Neural network architecture. The network is designed to learn and discriminate between
the unique acoustic patterns characteristic of each emotion class. Training is performed using supervised learning
techniques, with labeled emotion data guiding the network towards accurate classification.

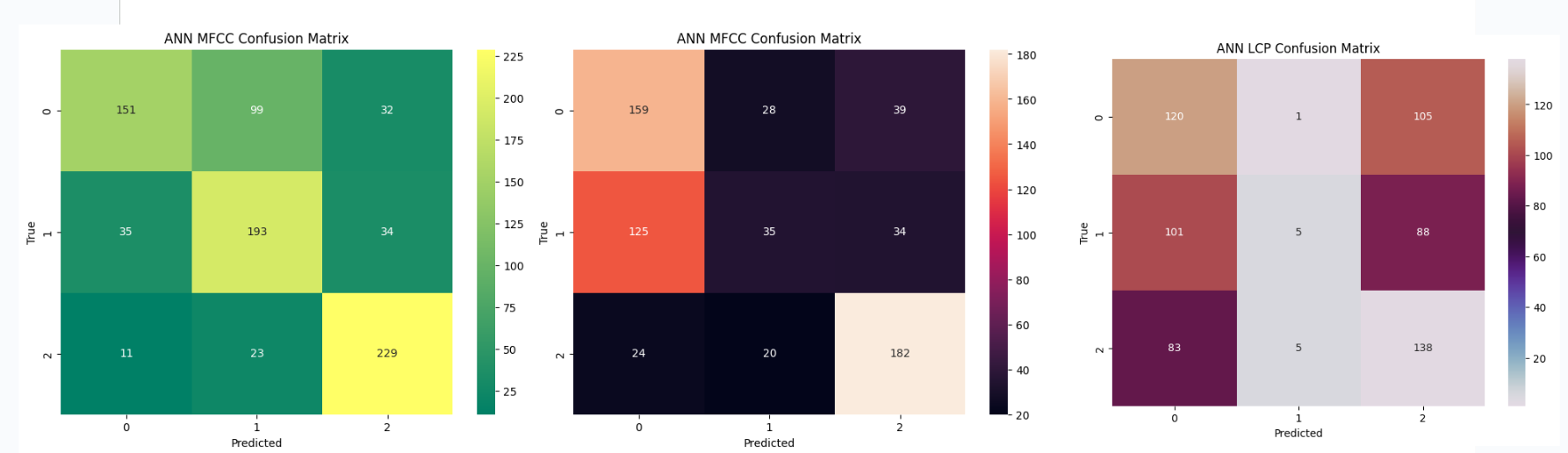
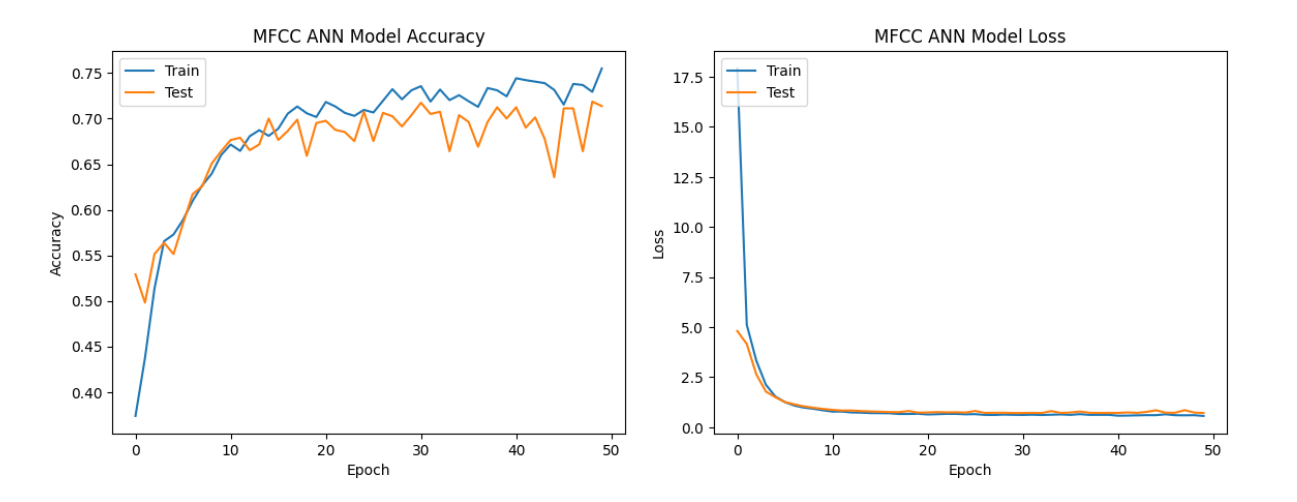
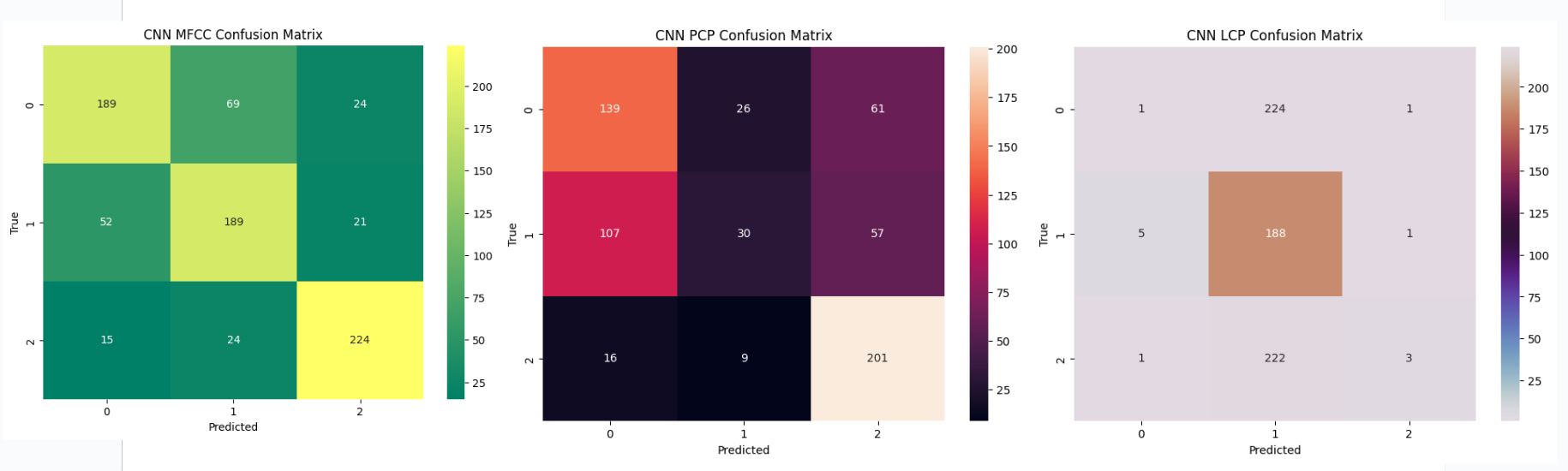

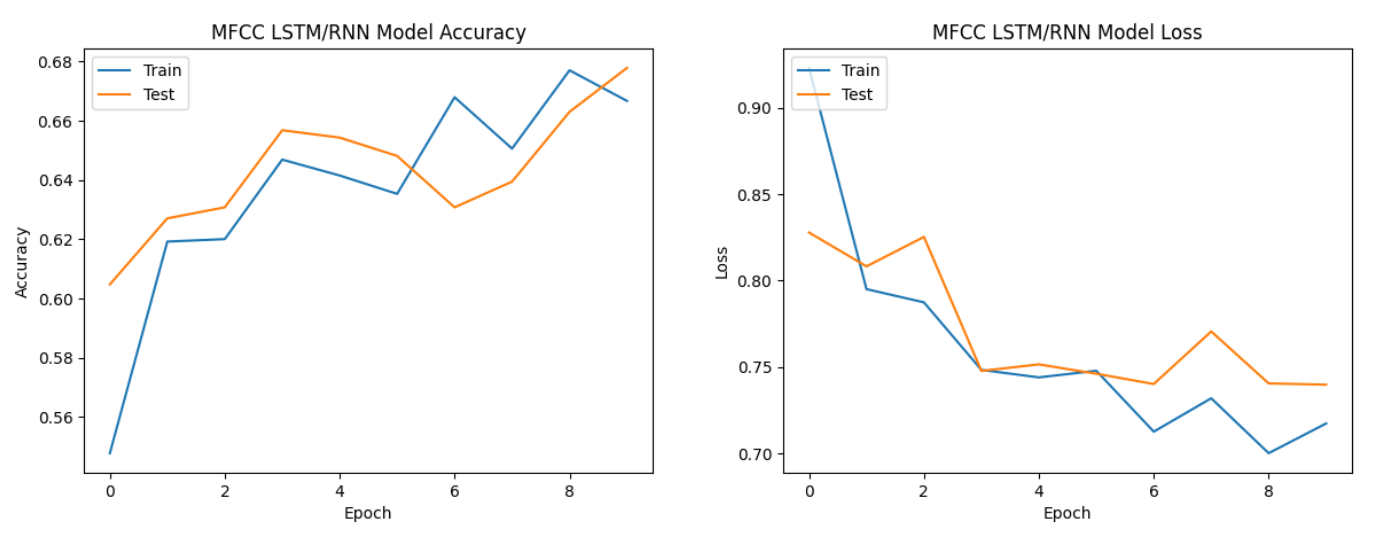
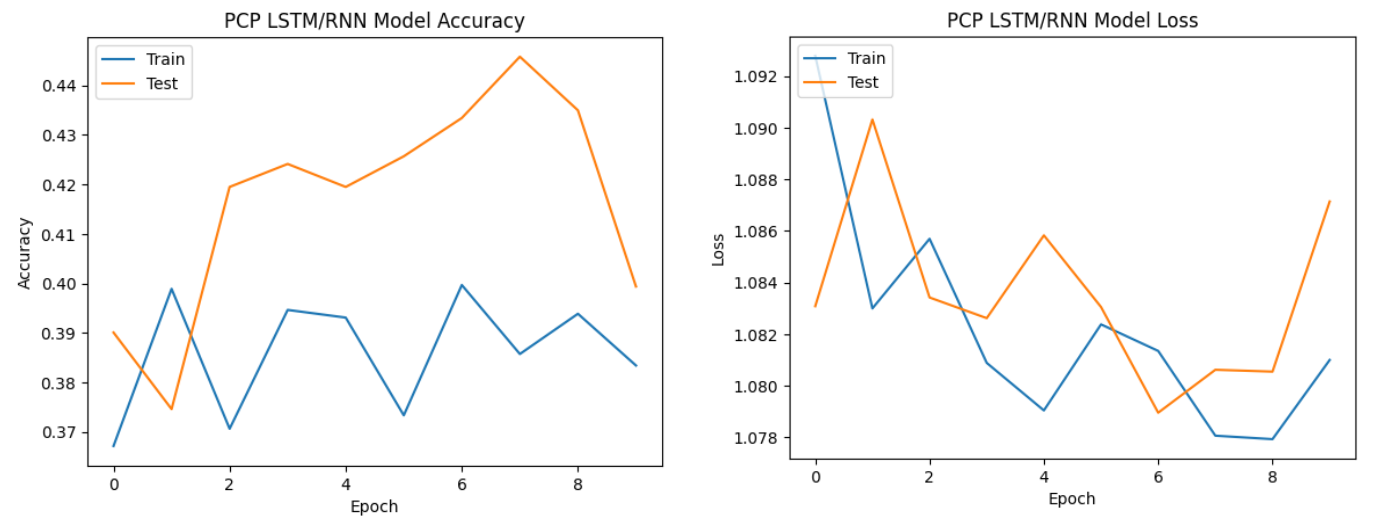
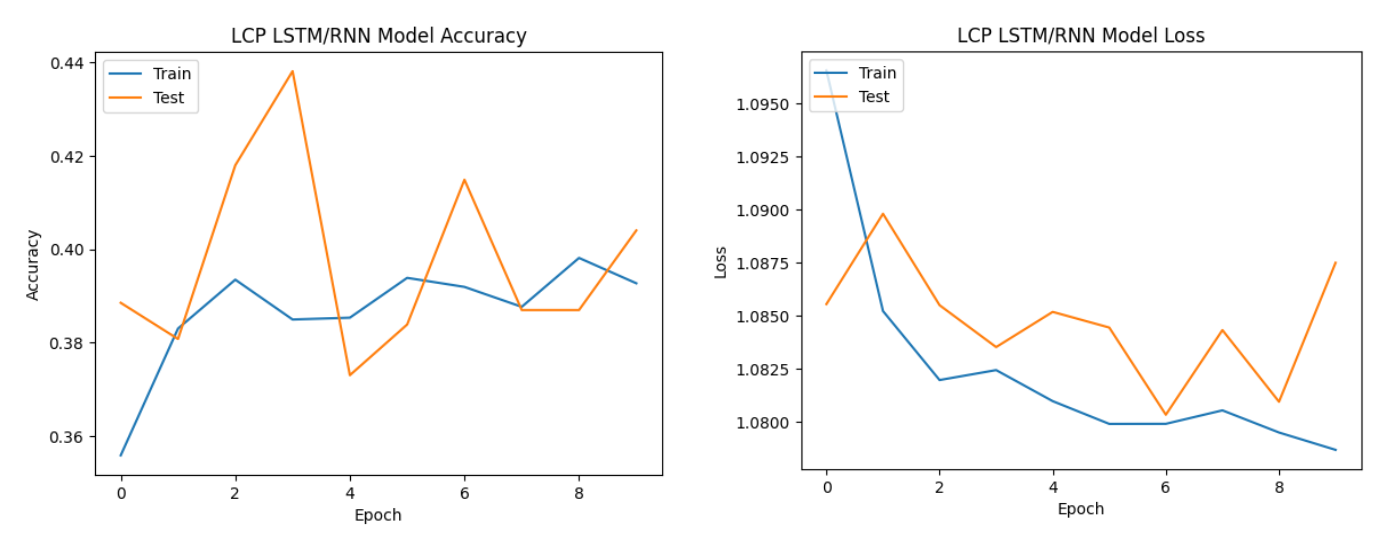
All three types of neural network models performed relatively well with MFCC features.
MFCC features, which capture spectral and temporal characteristics of audio signals,
seem to be effective for speech emotion analysis across all model architectures.
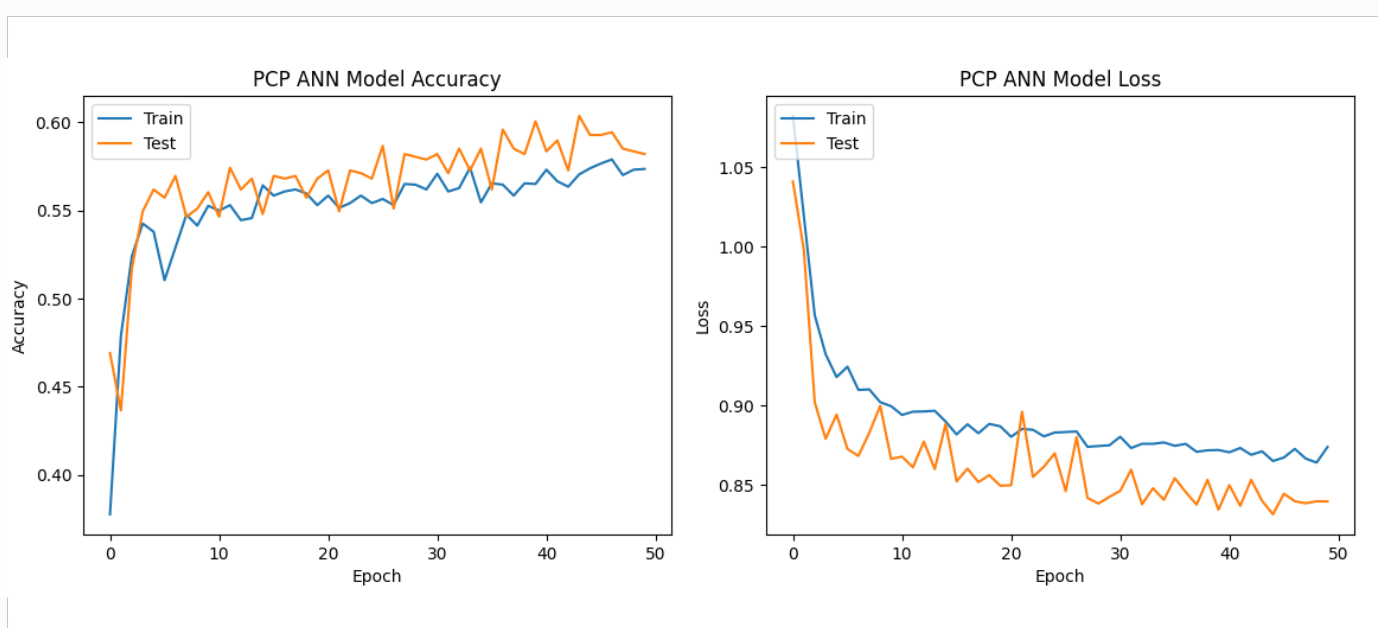
The performance with PCP features varied across models but generally resulted in moderate accuracy.
While PCP features showed reasonable performance, they did not consistently outperform
MFCC features, suggesting that they may not be as informative for speech emotion analysis in this context.
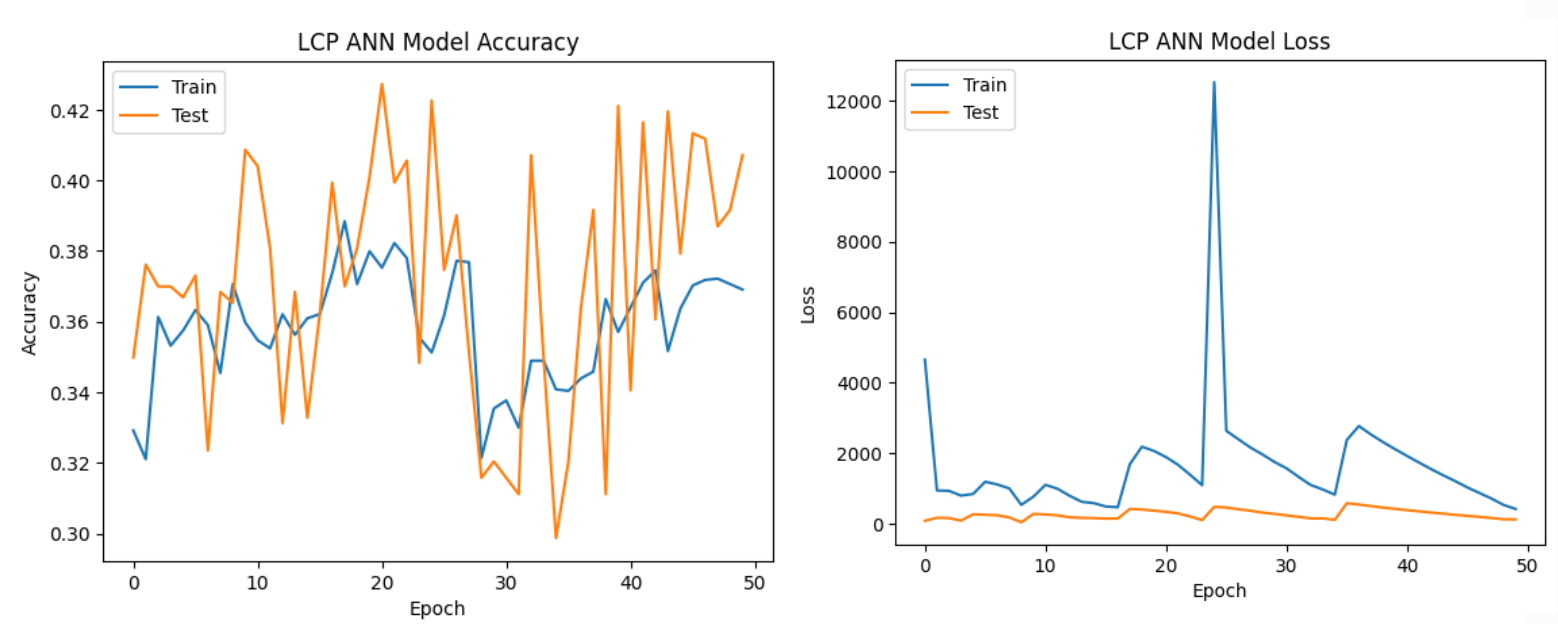
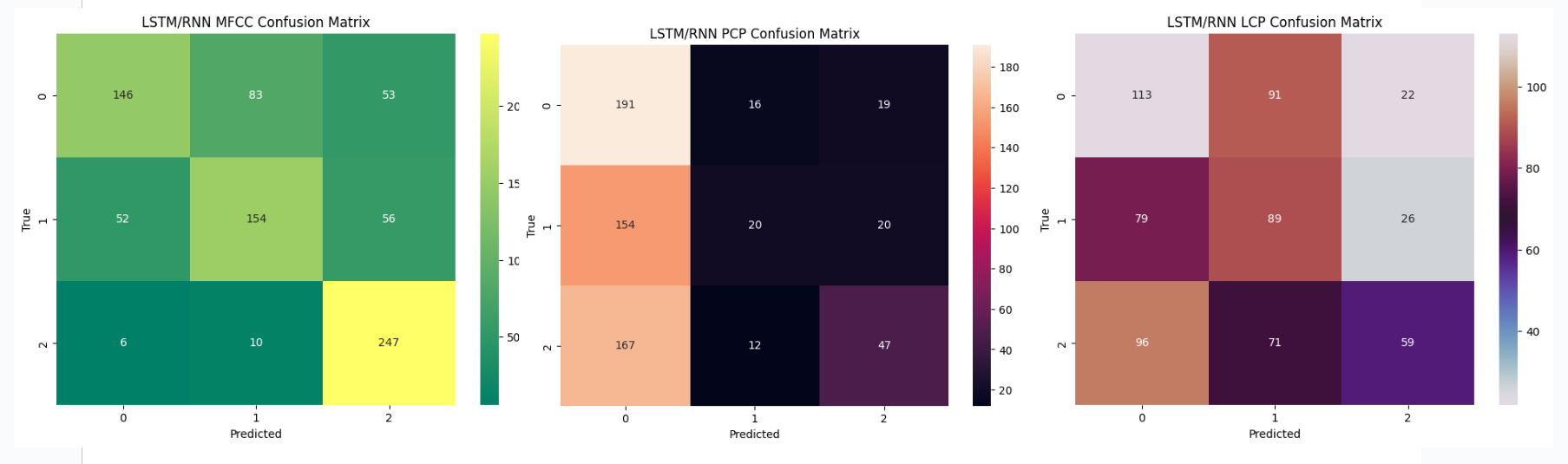
LCP features consistently yielded lower accuracies across all models.
The models struggled to effectively leverage linear predictive coding features,
indicating that these features might not be well-suited for capturing the nuances of speech emotions
in the given dataset.
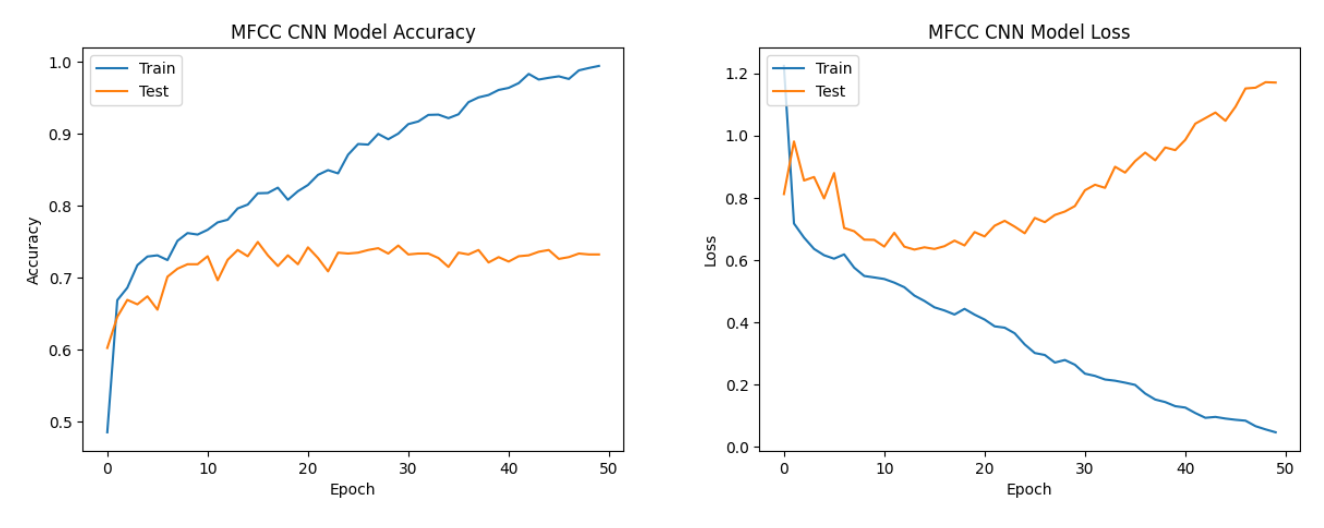
For speech emotion analysis, MFCC features consistently demonstrated the best performance across all three neural network architectures, indicating their effectiveness in capturing relevant patterns for this task.
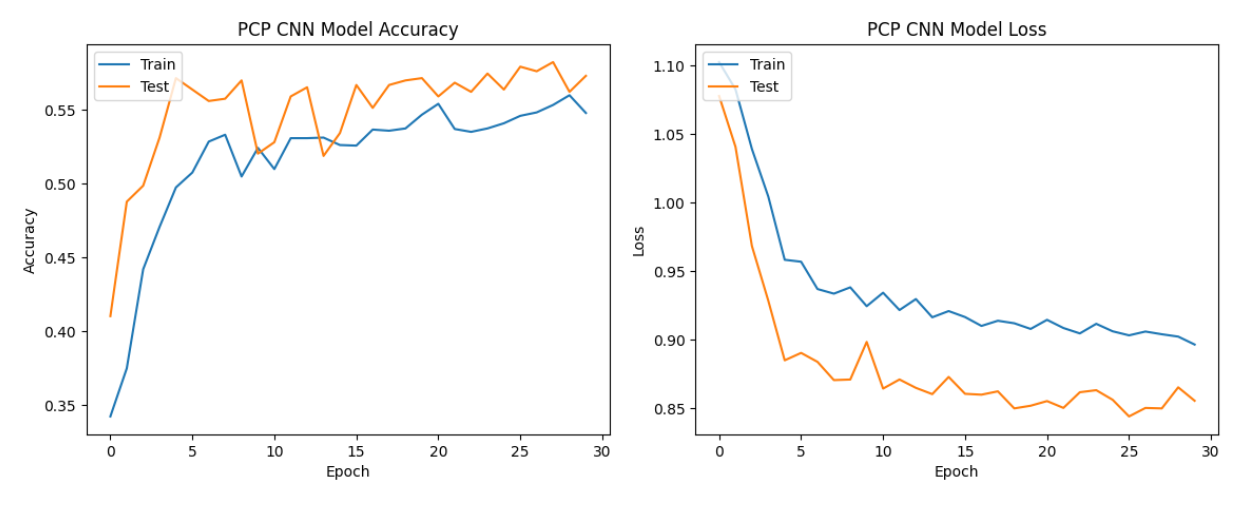
PCP features showed moderate performance, suggesting their potential utility but not reaching the same level of effectiveness as MFCC features.
LCP features consistently resulted in lower accuracies, indicating limited suitability for speech emotion analysis in the context of the employed models and dataset.
The choice of feature representation is crucial in audio-based tasks, and the success of MFCC features in this study suggests their importance
for capturing the discriminative characteristics of speech emotions.
| Model | Feature | Training Accuracy | Testing Accuracy |
|---|---|---|---|
| ANN | MFCC | 76.87% | 71.38% |
| PCP | 59.76% | 59.13% | |
| LCP | 37.57% | 40.25% | |
| CNN | MFCC | 99.83% | 73.23% |
| PCP | 56.35% | 57.12% | |
| LCP | 33.54% | 32.20% | |
| LSTM/RNN | MFCC | 66.58% | 63.57% |
| PCP | 51.70% | 51.55% | |
| LCP | 39.39% | 43.03% |